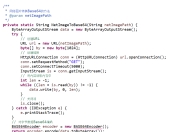
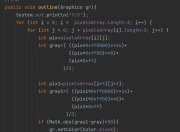
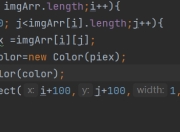
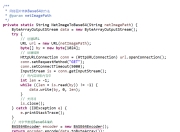
在Java开发中,GBK编码是处理中文字符的常见需求。作为中国国家标准GB 2312的扩展,GBK编码能够支持更多的汉字字符,成为处理简体中文的常用编码方式。然而,由于Java内部默认使用UTF-16编码,在实际开发过程中,GBK编码与UTF-8等其他编码方式的转换经常会导致中文乱码问题。本文将详细介绍如何正确使用GBK编码,避免乱码问题,帮助开发者更好地处理中文文本数据。
Java GBK编码转换的详细步骤
GBK编码的基本原理和特点
GBK编码全称为《汉字内码扩展规范》,它采用双字节编码方案,能够表示21003个汉字字符。与UTF-8相比,GBK编码具有几个显著特点:首先,GBK是定长编码(每个中文字符固定占用2个字节),而UTF-8是变长编码(中文字符通常占用3个字节);其次,GBK专门为中文设计,对中文文本的存储效率更高;最后,GBK兼容GB2312编码,但不兼容Unicode标准。
在实际应用中,GBK编码特别适合处理纯中文文本的场景,比如传统的Windows系统、某些遗留系统或特定行业应用。理解GBK编码的这些特性,对于java gbk编码转换至关重要,可以帮助开发者做出更合理的编码选择。
如何在Java中进行GBK编码转换
在Java中处理GBK编码主要涉及java.nio.charset包中的相关类。以下是进行GBK编码转换的基本步骤:
- 字符串到GBK字节数组的转换:
String chineseText = "中文测试";
byte[] gbkBytes = chineseText.getBytes("GBK");
- GBK字节数组到字符串的转换:
String decodedText = new String(gbkBytes, "GBK");
- 处理不同编码间的转换(如UTF-8转GBK):
String utf8Text = "UTF-8编码的中文";
byte[] utf8Bytes = utf8Text.getBytes(StandardCharsets.UTF_8);
String gbkText = new String(utf8Bytes, "GBK"); // 注意:这可能导致乱码
对于java gbk和utf-8的区别,开发者需要特别注意:直接在不同编码间转换字符串可能会导致数据丢失或乱码。正确的做法是明确知道源数据的编码格式,然后进行有意识的转换。
解决Java GBK乱码问题的关键方法
中文乱码问题是Java开发中常见的痛点,特别是在涉及文件读写、网络传输和数据库操作时。以下是几种常见的乱码场景及解决方案:
- 文件读取乱码:
当读取GBK编码的文本文件时,应明确指定字符集:
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream("gbkfile.txt"), "GBK"));
- HTTP请求/响应乱码:
处理HTTP请求时,可能需要设置请求和响应的字符编码:
// 设置请求编码
request.setCharacterEncoding("GBK");
// 设置响应编码
response.setContentType("text/html;charset=GBK");
- 数据库连接乱码:
连接数据库时,确保JDBC URL中指定了正确的字符集:
String url = "jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=GBK";
对于如何解决java gbk乱码问题,最关键的准则是:在任何文本数据的输入输出边界都明确指定字符编码,避免依赖平台默认编码。同时,建议在项目中使用统一的编码标准,减少不必要的编码转换。
实际项目中的Java GBK编码案例分析
让我们通过一个实际案例来展示2023年java gbk编码最佳实践。假设我们需要开发一个处理银行对账单的系统,银行提供的对账单文件是GBK编码的CSV格式。
案例背景:
- 输入:GBK编码的CSV文件
- 处理:Java程序读取并转换为UTF-8格式存储
- 输出:UTF-8编码的JSON文件
解决方案:
public void convertGBKCSVtoUTF8JSON(String inputPath, String outputPath) {
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(inputPath), "GBK"));
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(outputPath), StandardCharsets.UTF_8))) {
String line;
JSONArray jsonArray = new JSONArray();
while ((line = reader.readLine()) != null) {
String[] values = line.split(",");
JSONObject jsonObj = new JSONObject();
// 假设第一列是账号,第二列是金额
jsonObj.put("account", values[0]);
jsonObj.put("amount", values[1]);
jsonArray.put(jsonObj);
}
writer.write(jsonArray.toString());
} catch (IOException e) {
e.printStackTrace();
}
}
在这个案例中,我们明确处理了编码转换的边界:在读取时指定GBK编码,在写入时指定UTF-8编码。这种明确的编码处理方式可以有效避免乱码问题。
关于java gbk和utf-8哪个更好的问题,答案取决于具体应用场景。对于纯中文环境且不需要国际化的系统,GBK可能是更高效的选择;而对于需要支持多语言或国际化的系统,UTF-8无疑是更好的选择。
掌握Java GBK编码,提升开发效率,立即尝试这些方法吧!
通过本文的介绍,我们全面了解了GBK编码在Java中的应用。从基本原理到实际编码转换,从乱码解决方案到项目实践案例,希望这些内容能帮助开发者更好地处理中文编码问题。记住,编码问题的关键在于一致性——确保在整个数据处理流程中使用正确的编码,并在所有I/O边界明确指定字符集。
对于现代Java项目,虽然UTF-8已成为事实上的标准编码,但在处理遗留系统或特定行业应用时,GBK编码的知识仍然不可或缺。建议开发者在实际项目中根据具体需求选择合适的编码方式,并建立统一的编码规范,这样才能从根本上避免乱码问题的发生。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。